
RPAをやっていると、ある時点から、場合によっては最初から、避けて通れない道になるのが「書類のデータ化」即ち、OCRです。
今まで「OCR?なにそれ?」って感じだったのに、RPAに携わるようになってから急に使わなきゃいけなくなった!なんて方も多いのではないかと思います。
そして、RPAの普及に合わせるかのように、OCRも急激な進化を遂げています。
むしろ、歴史の長さを考えると、OCRの方が、近年の進歩の凄まじさは上でしょう。(起点をどこに置くかで変わりますが、日本では40年とか50年の歴史があると言われます)
この進化したOCRは、いわゆる「AI-OCR」として世間で注目されていますが、そもそもOCRってどういう技術なのか、どういう課題を持っている(いた)のかについて、解説していきたいと思います。
そもそもOCRって?
OCRはOptical character recognitionの略称で、日本語では光学文字認識と呼ばれます。(「OCR」という単語だけ覚えておけば大丈夫です)
要するに、紙に書かれた文字を電子データの文字列に起こしてくれるソフトです。
これがなければ、紙に書かれた情報は人間が全て手入力でシステムに登録することになります。
データ入力作業の業務負荷を劇的に軽減しているという点では、「自動化」を広義に捉えたとき、RPAの大先輩とも言えるかもしれません。
身近なOCR
まず、無意識に日常生活の中で接しているOCR技術を何点か紹介していきます。
銀行窓口の依頼書
ネットバンキングの普及や、決済・割り勘アプリの登場などによる送金手段の多様化で、最近は記入する機会がほとんどないと思いますが、銀行窓口の依頼書はOCR用の帳票です。
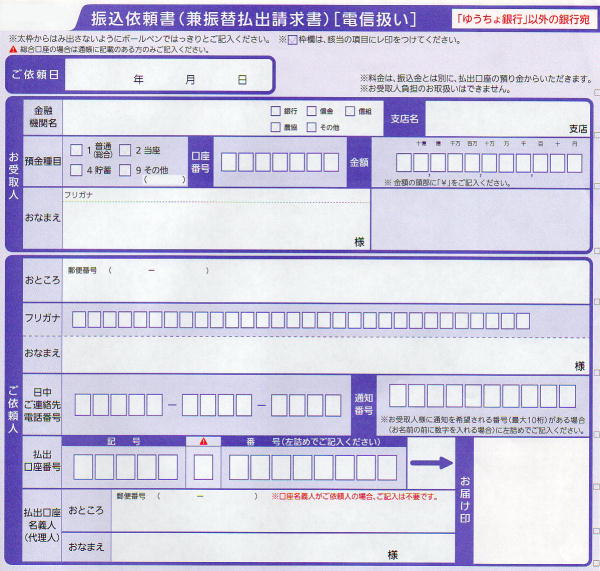
枠の位置が決められており、1文字1枠で記入するようにできています。
この枠を、バックオフィス側でOCRソフトが読み取って電子データにしてくれることで、人力での入力作業を省力化しています。
QRコード
QRコードも、文字の読み取りではありませんが、画像を解析してデータを引っ張ってくる、OCRの一種です。

ちなみに↑のコードを読み取ると・・・
このブログのTOPページに飛ばされます。
手書き入力パッド

WindowsでもIMEパッドで、読み方の分からない字を手書きで文字入力することができますよね。
これもOCR技術の上に成り立っています。
マークシートもOCRの仲間

各種試験などでお馴染みの「マークシート」は「OMR(光学式マーク読み取り装置)」という、OCRの親戚の技術です。
OCRから見れば下位互換のようなものなので、OCRソフトの中にはマークシート読み取り機能も具備しているものは多いです。
OCRの読み取りに重要な要素
OCRは、読み取った画像を解析し、文字データに変換します。
正確に文字を読み取れるかどうかを影響する要素は、多岐に渡っていますが、特に大きいのは以下の3つでしょうか。
OCRの精度に大きく影響する要素
-
WHAT:読み取り対象の記述方法(手書き/活字)
-
WEHRE:読み取り対象の特定方法(座標指定/キーワード抽出)
- HOW:文字枠の囲い方(固定ピッチ/フリーピッチ)
他にも精度に影響を与える要素は色々とありますが、特に影響の大きな3要素について、それぞれ解説していきます。
読み取り精度影響要素① 「What」 手書きvs活字
読み取り対象が「手書き文字」か「活字」か、は読み取り結果の精度に非常に大きな影響を与えます。
言うまでもなく、活字の方が遥かに高い精度が出ます。
フォントによる若干の差異はありますが、基本的には1種類の文字に対して1つの形状が定まっているためです。
これに対し手書きは、やはり人によってそれぞれの文字のクセがあるため、1つの文字でも実質、無限に文字パターンが存在してしまい、認識精度が極端に落ちてしまいます。
身近な例で挙げたWindowsの手書きパッドをイメージしてみましょう。

「千」という文字を書いてみたつもりですが、第一候補に現れたのは「チ」ですね。
画像として捉えれば、ほとんど同じ形をしている文字なのに、書く人が違えば別の文字を意図して書いていた、ということもあり得るくらいですから、OCRで手書き文字を読み取る難易度はどうしても上がってしまいます。
(これを解決する「AI-OCR」については、次回のエントリーで触れていきます)

読み取り精度影響要素② 「WHERE」 座標指定vsキーワード抽出
OCRに対して「画像のどこを読み取るか」 をどのように設定するかは非常に重要です。
基本形として多く用いられるのは、「読み取り範囲の座標を指定」するパターンです。
予め読み取る範囲を人間側で設定しておくので、スキャンで紙が大きくズレたといったことがなければ、欲しい情報をしっかり抽出してくれます。

ただし、座標定義によるOCRは様式が定まらない帳票に使えないという大きな弱点があります。
例えば、OCRと聞いて真っ先に試したくなるであろう請求書は、出してくる会社によって様式が異なります。
つまり、出してくる先によって請求額などの欲しい情報の書いてある位置がまちまちなので、座標定義が活かせないのです。
100種類あれば100の座標定義が必要ということでは、費用対効果は大きく損なわれてしまいます。
(取引先の上位3社だけで請求書の7割が占められてる、といったケースなら使う余地はありますが)
これを解決するもう一つの手法は「キーワード抽出」です。
例えば請求書であれば、読み取りたい情報は「請求額」などでしょう。
この場合は、「請求金額」「合計金額」などのキーワードを、OCRに紙全体から探してこい!と命令をすることになります。
欲しい情報はキーワードの近く(多くの場合はキーワードの右、そうでなければ下)に書かれていますから、そこを読み取りに行くわけです。

帳票のフォーマットを問わないため「フリーフォーマットOCR」などと言われますが、画像全体からの言語解析は、技術的には容易ではありませんでした。
しかし、こういった技術も、昨今のAIの発達などにより対応する製品も出てきています。
個人レベルで最も身近なのは、MoneyForwardのレシート読み取り機能ではないでしょうか。
読み取り精度影響要素③ 「HOW」 固定ピッチvsフリーピッチ
もう一つ重要なのが、各文字が枠で区切られているかです。
具体的には「1文字につき1枠」という風にボックスで区切られているかどうか、が重要になってきます。
「この枠の中にそれぞれ1文字ずつ入っているよ」
という前提で認識するのと、
「この枠の中に、何文字かわからないけど文字列が入ってくるよ」
という前提で認識するのでは、精度に差が出てきます。
OCRソフトが「どこまでが1つの文字か」を人間のように判断できないので、2つの文字をくっつけて1つの文字として読んでしまったり、逆に1つの文字を2つの文字に分解して読んでしまうためです。

この「1つの枠に不特定多数の文字が入っている状態」をフリーピッチと呼びます。(「1つの枠に1つの文字」と区切られているのが「固定ピッチ」)
活字の場合1つ1つの文字の幅が(フォントによるが)一定ですが、人間の手書きだと特に誤認識しやすいです。
その他の影響要素
■対象の文字種別(日本語/英語/数字/記号)
対象文字列は英数字か、日本語も混在するか、という事前設定も影響してきます。
例えば数字だけであれば、0~9の10種類の中から読み取り結果を導き出すので、手書きでもそれなりの精度が出たりします。
難しいのは「1」と「7」くらいですね。
英語が加わって「英数字」となった場合、「0(ゼロ)」「O(オー)」や「1(いち)」「I(アイ)」「l(エル)」も入ってくるので、活字でも誤認識する場合があります。
日本語が入ってきたらもう大変です。
1文字分の画像に対して、莫大な量の候補が挙がってきます。
OCR屋さんだって頑張っているので、活字であれば日本語でも高い精度は出せますが、やはり手書きだと、従来のOCRでは精度が落ちてしまいます。
■画像の精度
OCRは「画像」を「機械的に」認識していますから、汚い画像では上手く識別できません。
光が入って白飛びしてしまったら、白くなった部分を文脈で補うなんてことはできませんし、逆に画像が暗すぎれば、影まで文字の一部として読み込んでしまうこともあります。
あるいは、紙を斜めにスキャンしてしまったために違う文字に見えてしまうということもありますし、枠外のサインや印鑑が読み取りエリアに食い込んできて、読み取り時に一緒に文字の一部とみなしてしまったりします。
補足:ソフトにより能力差はありますが、斜めになった画像や影を補正するような機能も存在しています
きれいな画像として、位置ズレなども抑えるためには、業務用のスキャナで読み取った方が好ましいです。
RPAとOCRの親和性
RPAはあくまでシステムであり、扱うことができるのはアプリケーションと電子のデータです。
しかし、業務の現場でインプットとなるデータは、紙に打ち出されていることは少なくありません。
そのため、OCRで用意したデータをRPAでガンガン回していく、という超強力なタッグが成立します。

大昔からあるOCRの技術に注目が集まってきているのは、読み取り技術の進歩も当然ありますが、RPAによる再評価もその背景にはあるのです。
でも今ってペーパーレスの時代じゃないの?
電子化が進んでる時代だから、今更紙の読み取りなんてニーズ少ないんじゃないの?という人もいるでしょう。
そうは言うんですけどね、やっぱり紙ってなくなってないんですよね。
ペーパーレス化の流れで電子化されたのって、社内会議どまりの企業が多いんじゃないでしょうか?
顧客対応窓口だと、申込書の記入に紙とタブレットを選べるところなんかも増えてきていますが、やはり紙はまだまだほとんどのところで健在ですよね。
「紙じゃないと抵抗感を示す顧客が少なくない」というのは実際に窓口業務の設計に携わっている方から聞いたことがあります。
若い方ならそんなことはないんでしょうが、「電子媒体に個人情報を入力する=流出とかなんか怖い!」という心理が働いたりするのでしょう。
実際は紙に書いたものだって当然バックヤードで電子媒体に入力されてるわけですが…。
こういう話題だとなんとなく「これだから日本人は…」みたいな声も聞こえてきそうですが、UiPathとか海外製のRPAツールにもOCR機能を標準で持っていたりするわけですし、2018年にもなったところで、ExcelにOCR機能が付く、なんてあたり、世界的にも馬鹿にできないトレンドと言えるかもしれませんね。
まとめ
従来のOCRは、銀行や役場など特定の業務においては有用だけれど、帳票のフォーマットが固定されていなければならない、手書きには弱いなどの観点から、導入するほどの高い精度を得られず、膨大なマンパワーをかけて対処するしかないケースも存在していました。
「枯れた技術」と見る界隈もあったように思います。
しかし、RPAの登場で活躍の場は明確に増加しており、AI技術による飛躍的な性能の進歩もあって、捲土重来、現在は高い注目を集めています。
このようなツールと上手く付き合うことで、「自動化ライフ」の楽しみや歓びも増してくるんじゃないでしょうか。